Inside the AppSensa Stack
A behind-the-scenes look at how AppSensa runs on real devices, local LLMs, and a home-grown edge compute stack.

Building AppSensa has been unlike anything I’ve built before.
Normally I either work solo or lead a team of engineers. This time, I had a co-pilot: AI. It chewed through the grunt work and helped me move faster than I thought possible.
But the real twist? Most of AppSensa runs from my home, on an M4 Mac Mini, plugged into a cluster of real phones and emulators.
That’s not a quirky decision. It’s a deliberate one.
AppSensa does things with mobile apps that would be painful (or impossible) to do entirely in the cloud. We extract signals directly from real devices, which requires low-level control and stability. Long-running tasks need to keep running. And I don’t want to be held hostage by cloud quotas, billing surprises, or flaky ephemeral runners.
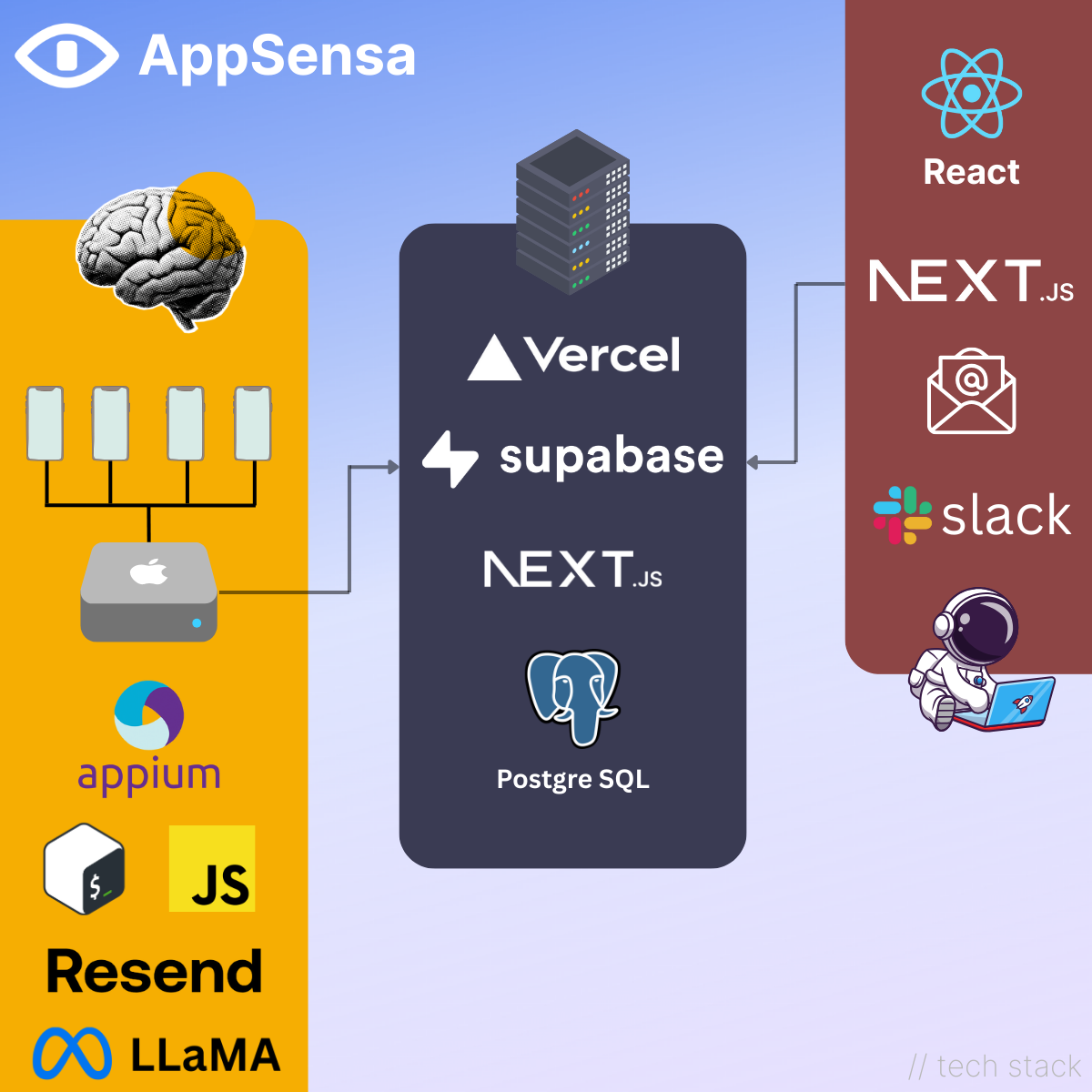
The AppSensa stack: local devices, local LLM, lightweight cloud
🧠 The Brain
The core of AppSensa runs on a single M4 Mac Mini:
- The Mac is connected to physical devices and a fleet of emulators
- Automation is handled via Appium (not for testing, we’re analyzing apps and uncovering hidden behavior)
- A combination of Bash scripts and JavaScript powers the orchestration, working alongside a local Llama 3 model to extract insights
- The M4’s CPU and GPU handle both compute-heavy analysis and on-device LLM inference
- Even Slack and email delivery happens locally, the Mac handles the full loop
One common question I get: why an M4 Mac Mini?
Simple. It just works incredibly well as a server. No complicated setup, no flaky drivers, no random hangs. Remote access is smoother from another Mac than any other OS I've used. And Apple Silicon delivers unbeatable performance per dollar, for both CPU-heavy and GPU-accelerated tasks like running a local LLM. It’s been the most reliable part of the system by far.
Scaling? Just plug in another Mac Mini and go. Each one is an independent compute node.
☁️ Backend
The backend is intentionally minimal:
- Hosted on Vercel for simple, scalable serverless APIs
- Uses Supabase for authentication and a persistent Postgres database
- No long-running tasks, just a coordination layer that stays out of the way
Because the backend is so lightweight, it’s easy to iterate, deploy, and scale as needed.
👤 Frontend
Same philosophy here — keep it lightweight and focused:
- Built with Next.js
- Users receive most insights via Slack or email, not through the UI
The frontend serves as a control panel, not a dashboard. It exists to configure, not consume.
Why This Stack Works
This setup gives me speed, control, and resilience.
The “hard” parts, digging through mobile apps and surfacing early signals, run on hardware I fully control. That means I can move fast, debug deeply, and avoid unnecessary abstractions.
Because the cloud side of the stack is so simple, I spend my time where it matters: building the intelligence that makes AppSensa work.
This is what lets AppSensa surface product changes before the world sees them.

